ScholarRAG
Sistema RAG para Educação Focado em uma arquitetura Open Source

Sobre o Projeto
Sistema inteligente de recuperação de informação que utiliza LLMs para responder perguntas baseadas em documentos científicos. O projeto aborda o problema das 'alucinações' em IA através de uma pipeline rigorosa de processamento de dados e avaliação sistemática de métricas de fidelidade.
Período
Ago 2024 - Dez 2025
Status
Cargo
Pesquisador & Engenheiro de Software (TCC)
Tecnologias
ScholarRAG: Inteligência Artificial a serviço da educação séria
A educação sempre foi o pilar central da minha trajetória. Como filho de professora, cresci acompanhando de perto os desafios da sala de aula e a importância de um suporte pedagógico de qualidade. Com a recente ascensão da Inteligência Artificial, notei uma dor crescente: o risco de alunos serem prejudicados pelo uso irresponsável dessas ferramentas, que muitas vezes entregam informações imprecisas ou desconectadas da realidade acadêmica.
O ScholarRAG nasceu do desejo de transformar essa tecnologia em uma aliada séria e cientificamente fundamentada. Este projeto, que serviu como meu Trabalho de Conclusão de Curso em Sistemas de Informação na Universidade Federal de Uberlândia (UFU), investiga como podemos oferecer respostas precisas utilizando a arquitetura de Recuperação Aumentada por Geração (RAG).
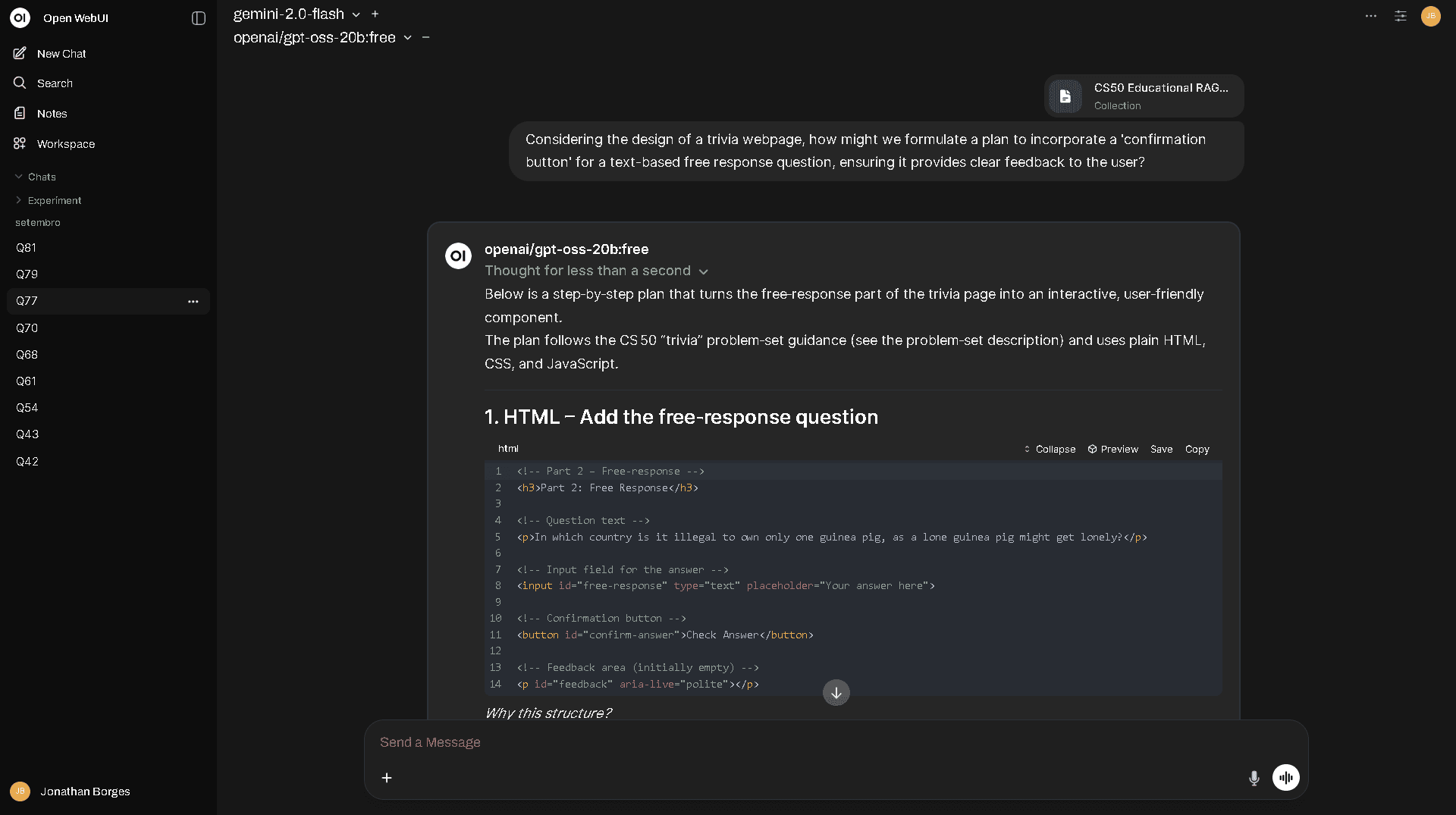
Interface do ScholarRAG integrada ao OpenWebUI, demonstrando a interação direta com o material didático.
O problema das alucinações e a memória externa
Modelos de linguagem genéricos costumam sofrer com o que chamamos de "alucinações", gerando fatos que parecem verídicos, mas são inventados. Em um contexto educacional, onde o aprendizado depende de fatos concretos e fontes confiáveis, esse comportamento é inaceitável.
Para resolver esse problema, o ScholarRAG não confia apenas na "memória" interna do modelo de IA. O sistema atua como um pesquisador que, antes de responder ao aluno, consulta uma base de dados de confiança. Para este estudo, utilizei o conteúdo integral do curso CS50 de Harvard, incluindo transcrições de vídeo-aulas, notas de estudo e exercícios. O objetivo foi garantir que cada resposta fosse estritamente baseada no material didático oficial, eliminando invenções do modelo.

Fluxo macro da arquitetura RAG: da consulta do usuário à recuperação de documentos e geração da resposta final.
Arquitetura e escolhas tecnológicas
A construção desta solução exigiu uma infraestrutura que priorizasse a soberania tecnológica e o uso de ferramentas de código aberto. A stack foi selecionada para garantir que o sistema pudesse rodar de forma eficiente e modular, permitindo a substituição de componentes conforme a necessidade.
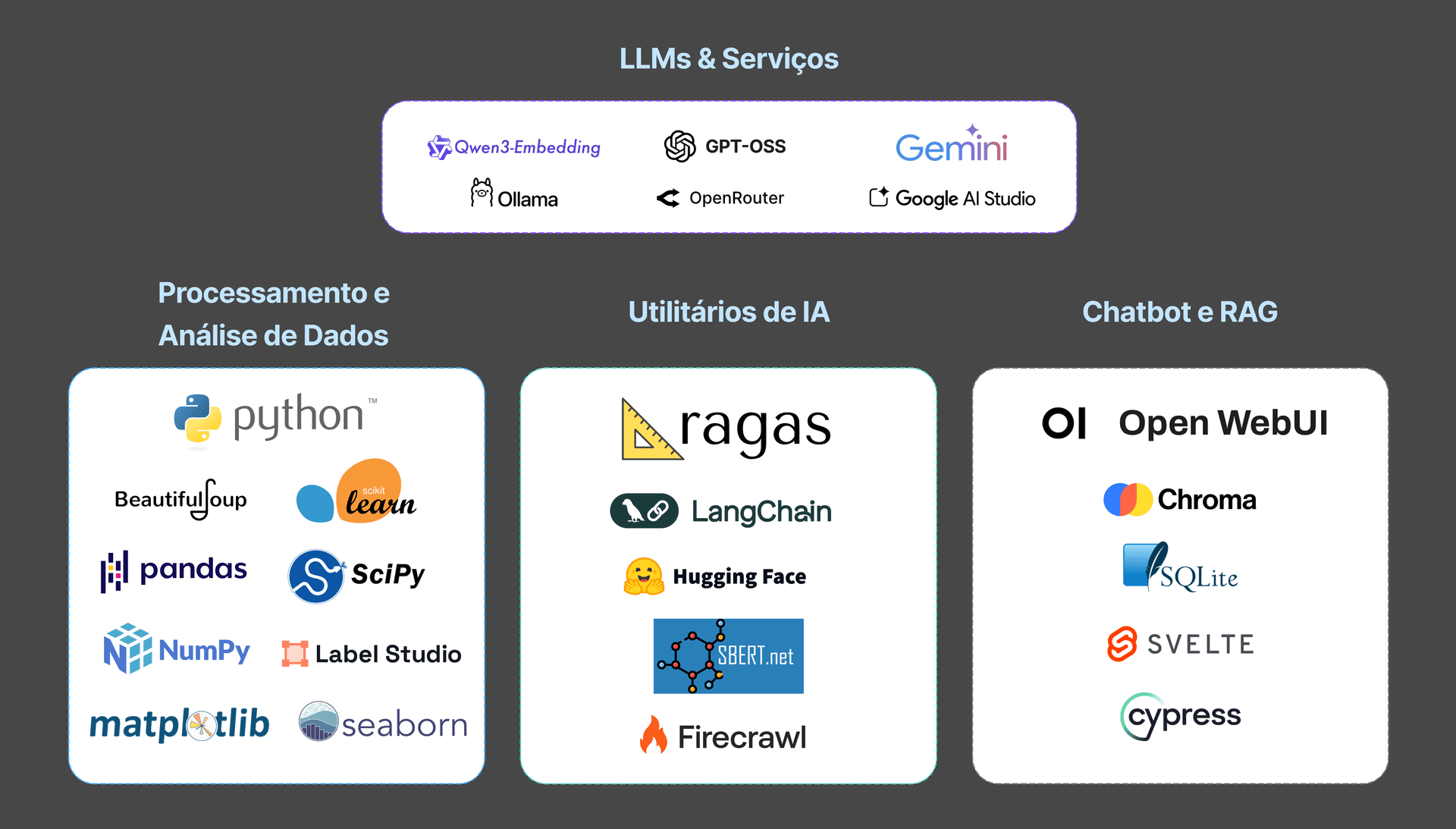
Ecossistema de ferramentas utilizadas, destacando Python para lógica, ChromaDB para persistência vetorial e Ollama para execução de modelos locais.
O fluxo de trabalho foi dividido em três frentes principais:
Orquestração: Utilizei o OpenWebUI para gerenciar a interface e o fluxo de conversação entre o aluno e a máquina.
Processamento e Busca: Implementei o ChromaDB como banco de dados vetorial, permitindo que o sistema localize rapidamente os trechos mais relevantes do material didático para responder à dúvida específica do usuário.
Modelos de Linguagem: O sistema foi testado integrando modelos como o Gemini-2.0-Flash e o GPT-OSS-20B, rodando parte da operação localmente via Ollama para garantir privacidade e baixo custo.
Engenharia de dados: do bruto ao estruturado
Um sistema de IA é tão bom quanto os dados que o alimentam. Desenvolvi um pipeline em Python utilizando ferramentas como BeautifulSoup e Firecrawl para minerar o conteúdo do curso CS50. O desafio técnico foi converter conteúdos heterogêneos e desestruturados em arquivos Markdown padronizados, enriquecidos com metadados para que o sistema soubesse exatamente a origem de cada informação (aula, semana ou tópico).
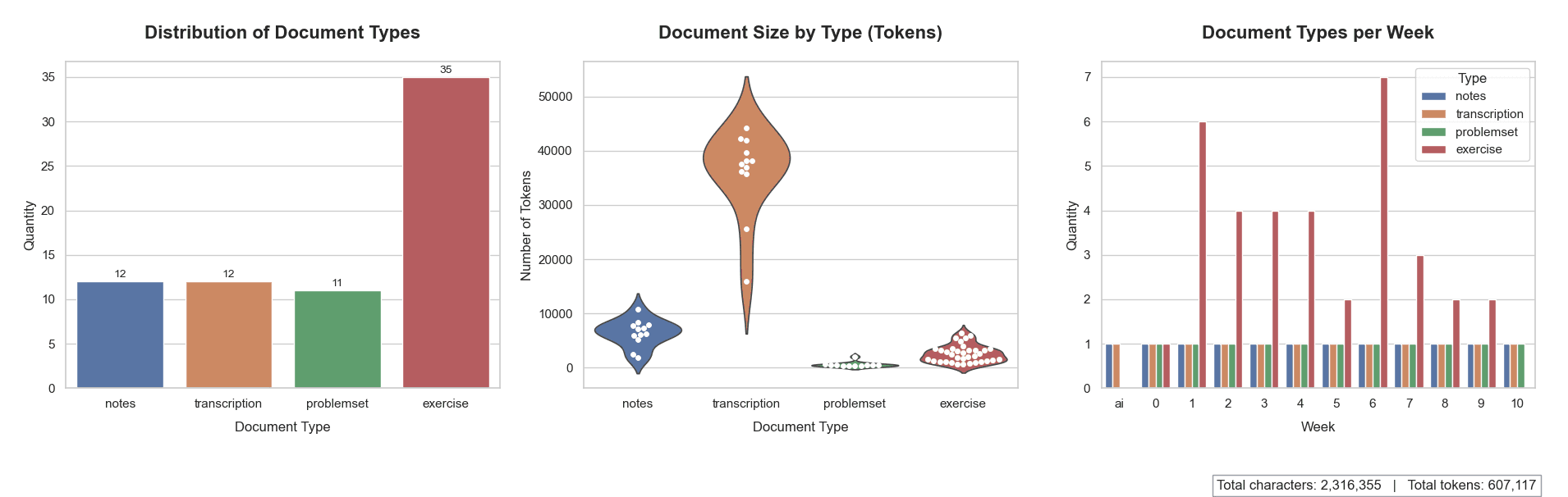
Análise quantitativa do dataset extraído, mostrando a distribuição de tokens e a estrutura dos documentos após o tratamento dos dados brutos.
Validação científica e a Taxonomia de Bloom
Diferente de um chatbot comum, o ScholarRAG foi submetido a um rigoroso processo de avaliação. Para testar se o sistema realmente auxiliava o aprendizado sem comprometer a integridade pedagógica, utilizei a Taxonomia de Bloom para gerar perguntas sintéticas que simulassem diferentes níveis de complexidade cognitiva, desde a simples memorização de conceitos até a análise crítica.
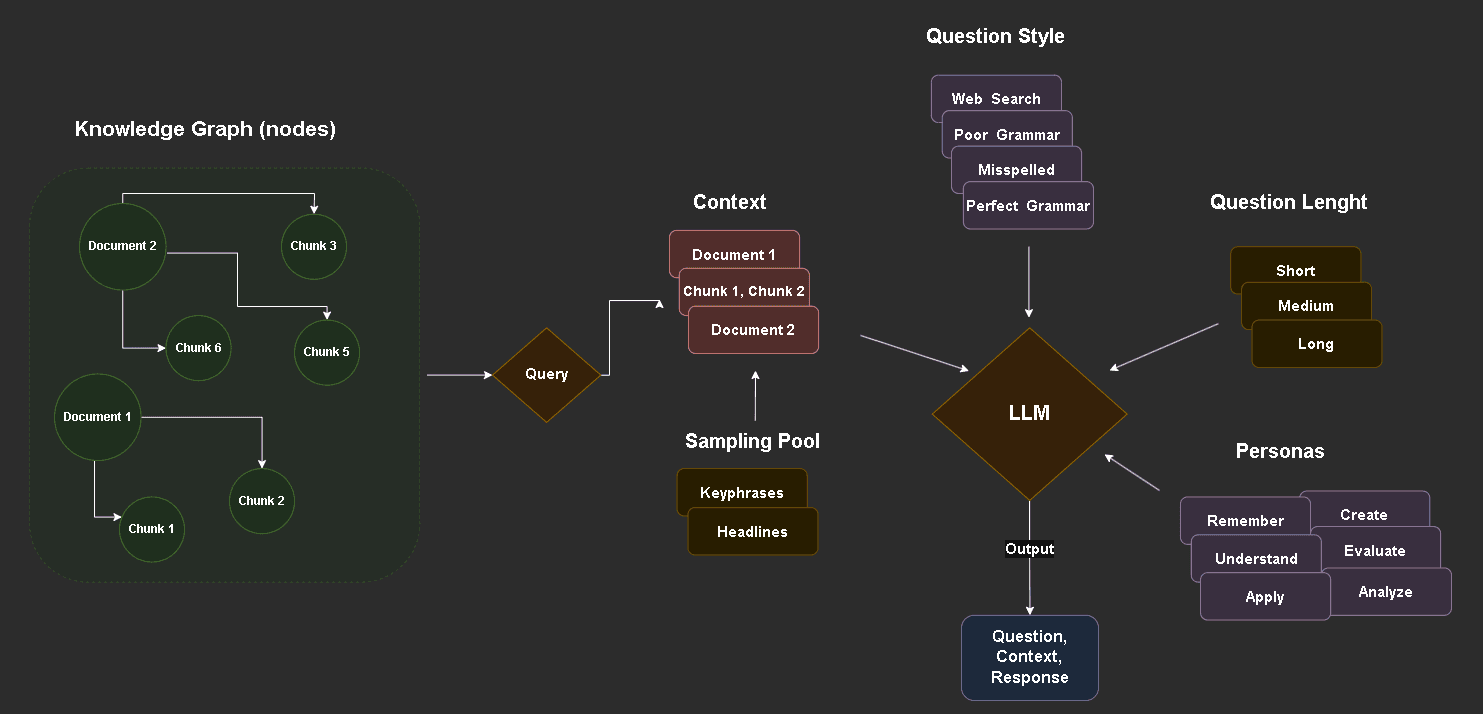
Pipeline de geração de dados sintéticos utilizado para criar perguntas de teste baseadas em diferentes níveis de complexidade cognitiva.
Utilizei o framework Ragas para medir a qualidade das respostas através de três pilares fundamentais:
Fidelidade: A resposta é sustentada pelo material de estudo original?
Relevância: A IA realmente respondeu o que o aluno perguntou de forma direta?
Correção Factual: O conteúdo gerado está alinhado com o gabarito oficial da disciplina?
Validamos essas métricas automáticas comparando-as com avaliações de especialistas humanos, encontrando correlações estatísticas que comprovam a utilidade do sistema como um tutor pedagógico confiável.
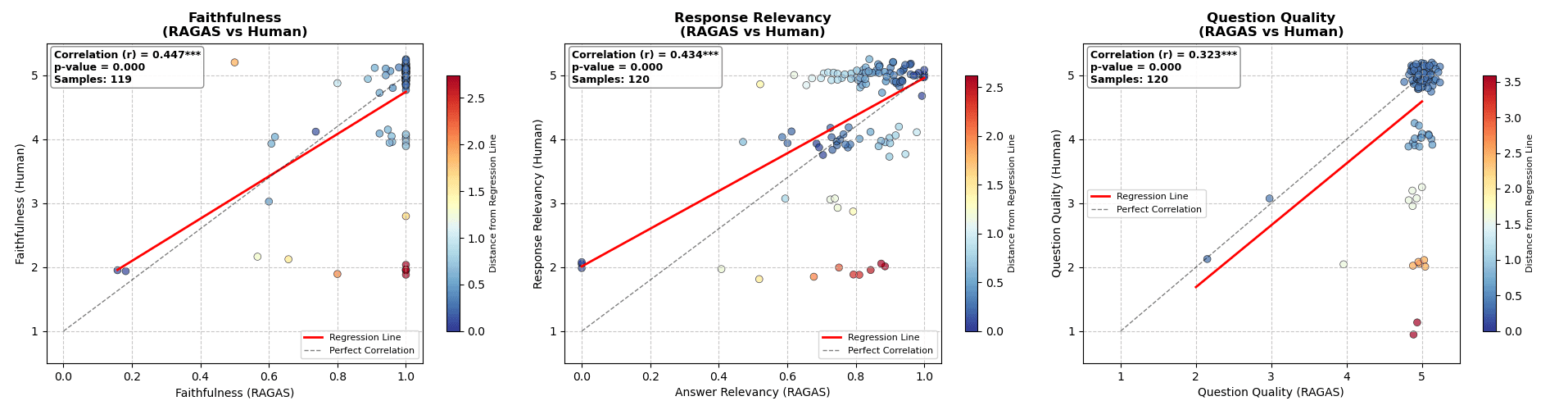
Gráficos de correlação entre as métricas automáticas do framework Ragas e a avaliação de especialistas humanos, validando a precisão do sistema.
Contribuições para a comunidade e conclusão
Contribuí para a biblioteca open source RAGAS (+900k downloads mensais), adicionando rastreabilidade de dados sintéticos gerados, testes unitários e corrigindo bugs de execução do CI/CD. Experiência com desenvolvimento colaborativo através de padrões de qualidade em projetos open source.
O ScholarRAG é a prova de que a tecnologia, quando guiada pela ética pedagógica e pelo rigor científico, pode ampliar a capacidade do educador e oferecer um suporte personalizado, seguro e profundo para o estudante.
Recursos do Projeto
Repositório Principal: Contém todo o código de geração de QA, análises e execução do chatbot. Acessar GitHub
Coleta de Dados: Scripts específicos para web scraping, parsing e formatação do conteúdo do CS50. Acessar GitHub
Dataset Publicado: Repositório no Hugging Face com os dados finais e curados para uso da comunidade. Acessar Hugging Face
Artigo Científico: Estudo completo com toda a fundamentação teórica e resultados detalhados. Ler Paper no Repositório UFU
